
Технологии интеллектуального анализа данных (ИАД)
Под ИАД следует понимать сложный анализ "очищенных" данных с использованием математических методов машинного обучения, таких как: статистические методы, нейронные сети, искусственный интеллект, генетические алгоритмы, деревья решений и т. д., а также, результаты их применения - методов представления данных. Смысл использования сложного анализа данных сведен к формулировке "получения новой информации из данных".
К информационным технологиям ИАД сегодня относятся:
I. Оперативный анализ данных
В основе концепции OLAP-систем лежит принцип многомерного представления данных: каждое числовое значение, содержащееся в ИХ, может иметь до нескольких десятков (сотен) атрибутов. Одним из существенных недостатков реляционной модели БД является невозможность объединять, просматривать и анализировать данные с точки зрения многомерности измерений, то есть наиболее понятным для аналитиков способом. С целью расширения функциональных возможностей традиционных реляционных СУБД следует включить многомерный анализ как одну из характеристик, так как: "реляционные БД были, есть и будут наиболее подходящей технологией для хранения корпоративных данных. Необходимость существует не в создании новой технологии разработки баз данных, а в средствах анализа, дополняющих функции существующих СУБД и достаточно гибких, чтобы автоматизировать интеллектуальную деятельность руководителя".
Многомерное представление данных представляет собой множественную перспективу, состоящую из нескольких независимых измерений, вдоль которых могут быть проанализированы определенные совокупности данных. Одновременный анализ по нескольким измерениям определяется как многомерный анализ. Каждое измерение включает направления консолидации данных, состоящие из серии последовательных уровней обобщения, где каждый вышестоящий уровень соответствует большей степени агрегации данных по соответствующему измерению.
По типу используемой базы данных все OLAP-системы делятся на три класса:
1. Системы оперативной аналитической обработки многомерных баз данных (или MOLAP-системы), в которых данные организованы не в форме реляционных таблиц, а в виде упорядоченных многомерных массивов:
1. гиперкубов - все хранимые в БД ячейки должны иметь одинаковую мерность, то есть находиться в максимально полном базисе измерений;
2. поликубов - каждая переменная хранится с собственным набором измерений, и все связанные с этим сложности обработки перекладываются на внутренние механизмы системы.
2. Системы оперативной аналитической обработки реляционных баз данных (или ROLAP-системы) позволяют представлять данные в многомерной форме, обеспечивая преобразование информации в многомерную модель через промежуточный слой метаданных.
3. Гибридные системы оперативной аналитической обработки данных (Hybrid OLAP, HOLAP-системы) разработаны с целью совмещения достоинств и минимизации недостатков предыдущих систем. Они объединяют аналитическую гибкость и скорость ответа MOLAP-систем с постоянным доступом к реальным данным, свойственным ROLAP-системам.
II. Исследование данных (Data Mining)
Основная цель технологии – поиск и выявление в данных скрытые связи и взаимозависимости с целью наглядного предоставления их руководителю в процессе принятия решения. Технология включает в себя методы поиска новой информации в данных, подразумевающие использование математических алгоритмов (статистика, оптимизация, корреляция и др.), позволяющих находить эти зависимости и синтезировать дедуктивную информацию.
III. Извлечение знаний из баз данных (Knowledge Discovery in Databases)
Технология представляет новое направление в области ИАД, где процесс поиска закономерностей в данных рассматривается как процесс машинного обучения. Технология объединяет в себе вопросы моделирования закономерностей и зависимостей в базах данных и определяет математические методы построения систем "открытия" (извлечения, добычи) новых данных на основе методов классификации, кластеризации, построения деревьев решений и др.
Таким образом, основу СИППР составляет интегрированное сочетание технологии накопления и хранения данных на основе информационных хранилищ с технологией интеллектуального анализа данных. Концептуальная модель системы интеллектуальной поддержки принятия решений представлена на рисунке.
Основными компонентами концептуальной модели СИППР являются:
- Информационное хранилище данных.
- Средства погружения данных.
Одним из основных требований, предъявляемых к этим средствам, является обеспечение возможности доступа к различным источникам данных, что обеспечивается за счет использования универсального интерфейса доступа к данным (например, типа ODBC, OLE DB и т.д.).
- Витрины данных.
- Генераторы запросов, информационно-поисковые системы в области детализированных данных, нацеленных на поиск информации в реляционных СУБД.
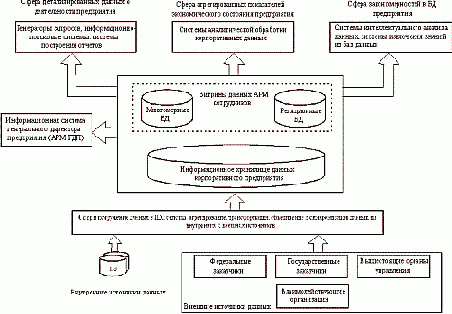
Рисунок 1. Концептуальная модель системы интеллектуальной поддержки принятия решений
- Системы аналитической обработки агрегированных показателей. Предназначены для многомерного представления и последующего анализа данных.
- Системы ИАД и системы извлечения знаний из ИХ. Главными задачами являются поиск функциональных и логических закономерностей в накопленной информации, а также построение аналитических моделей и решающих правил, которые объясняют выявленные взаимосвязи и способны прогнозировать развитие бизнес-процессов.
Следует отметить, что зарубежные страны занимают лидирующее положение в области разработок и внедрения во все жизненные сферы СППР, ориентированных на интеллектуальную обработку данных. Одними из немногих примеров информационных систем, реализующие методы ИАД, их предназначение и возможности являются:
- Система "Darwin", разработанная компанией Thinking Machines (Бедфорд, шт. Массачусетс) позволяет строить модели на основе нейросетей и деревьев решений, а также использовать методы визуализации и классификации данных.
- Пакет "PowerPlay 5.0" фирмы Cognos - выполняет многомерный анализ данных, включающих до двух и более миллионов записей, в масштабе корпоративного предприятия (свыше 2000 пользователей). Система позволяет: построение трехмерных графиков и диаграмм, ранжирование данных, немедленный возврат к верхнему уровню иерархии данных и систем меню, полностью определяемых ЛПР.
- ROLAP-cистема "DSS Agent" компании MicroStrategy (Виенна, шт. Виргиния) представляет для построения ИХ интегрированный набор инструментов и методов объединения данных из разнородных источников.
- Проект "Pablo for Windows" фирмы Andyne Computing (Кингстон, Канада) представляет СППР, позволяющую просматривать обобщенные выборки на основе данных из реляционных баз данных и манипулировать ими.
- Программный пакет "Integrity Data Re-engineering Tool" производства компании Vality Technology. Представляет среду программирования, используемую для исследования, стандартизации и интегрирования данных из различных источников. "Integrity" выявляет новую информацию и наборы правил из оперативных данных, что позволяет разработчикам ИХ планировать и определять модели данных, которые бы правильно отображали сложности реального мира.
- Продукты хранения данных фирмы Red Brick Systems, позволяющие: быстро разрабатывать и устанавливать приложения для управления; строить запросы к БД любого размера с информацией, собранной от разнородных источников; обеспечивать наилучший доступ к обобщающей и детальной информации в единой базе данных.
1. Нейронно-сетевой пакет "STATISTICA Neural Networks" компании StatSoft-Россия, предоставляющий возможность автоматически получать эффективные решения слабоструктурированных задач, в которых использование традиционных статистических методов является нерациональным.
В системе реализован полный набор архитектур сетей, алгоритмов обучения (методы обратного распространения, квази-ньютоновский, Левенберга-Маркара, Кохонена, квантования обучающего вектора и др.), мощные средства визуализации данных, помогающие оценивать качество работы сети и строить прогнозы. Кроме того, в систему заложены, генетические алгоритмы отбора входных данных, а также полный интерфейс прикладного программирования (API), позволяющий включать нейронные сети в другие приложения. На основе методов искусственного интеллекта реализован "Мастер решения задач", позволяющий автоматизировать выбор наилучшей архитектуры и построение сети.
2. Система "PolyAnalyst", представленная российской компанией Megaputer Intelligence в качестве инструментария для автоматического извлечения из данных решающих правил, зависимостей и других знаний, на основе которых могут приниматься управляющие решения.
В основе "PolyAnalyst" лежит набор методик и алгоритмов анализа данных - как традиционных, так и современных - метод автоматического обнаружения размытых нелинейных зависимостей и инструментарий построения произвольных нелинейных регрессионных моделей методами эволюционного программирования.
3. OLAP-средства, в качестве приложений, внедряют в свои системы такие лидеры российского информационного рынка как "1 C", "Парус" и другие.
Нельзя не отметить и нашедшие широкое распространение CASE-средства, предназначенные для разработки подобных систем. Большую популярность завоевал такой продукт как ERwin® 4.0 (http://www.interface.ru/fset.asp?Url=/ca/news/pr010124798.htm) – представляющий промышленный инструментарий для моделирования данных, разработанный для поддержки структурного подхода к управлению информацией.
Таким образом, в основе всех современных систем лежат различные математические методы теории машинного обучения или совокупность нескольких. На текущий момент проведение исследований в области машинного обучения с целью разработки новых и модернизации старых методов является наиболее альтернативным подходом для создания АСУ нового поколения – систем интеллектуальной поддержки принятия решений.